




Python is one of the most popular programming languages among developers, but it has certain limitations. For example, depending on the application, it can be up to 100 times as slow as some lower-level languages. That’s why many companies rewrite their applications in another language once Python’s speed becomes a bottleneck for users.
PyPy is a very compliant Python interpreter that is a worthy alternative to CPython 2.7, 3.6, and soon 3.7. By installing and running your application with it, you can gain noticeable speed improvements. Historically, PyPy has been used to mean two things. The first is the RPython translation toolchain for generating interpreters for dynamic programming languages. And the second is one particular implementation of Python produced with it. Because RPython uses the same syntax as Python, this generated version became known as Python interpreter written in Python. It is designed to be flexible and easy to experiment with.
The examples in this article use Python 3.6 since that’s the latest version of Python that PyPy is compatible with.
This article covers:
- Installation of PyPy
- How to run your python code with PyPy
- How PyPy compares with CPython in terms of speed
- Features of PyPy
- Limitations of PyPy
CPython has certain limitations and won’t win any medals for speed. That’s where PyPy can come in handy. Since it adheres to the Python language specification, PyPy requires no change in your codebase and can offer significant speed improvements thanks to the features you’ll see below.
Now, you may be wondering why CPython doesn’t implement PyPy’s awesome features if they use the same syntax. The reason is that implementing those features would require huge changes to the source code and would be a major undertaking.
Installation
On Linux :
$ sudo apt install pypy3 pypy3-dev
On Mac :
$ brew install pypy3
Or you can download a prebuilt binary for your OS and architecture. Once you complete the download unpack the tarball or ZIP file. Then you can execute PyPy without needing to install it anywhere.
$ tar xf pypy3.6-v7.3.1-osx64.tar.bz2
$ ./pypy3.6-v7.3.1-osx64/bin/pypy3
Before executing the code above, you need to be inside the folder where you downloaded the binary. Refer to the PyPy's installation documentation for the complete instructions.
PyPy in Action
You now have PyPy installed and you’re ready to see it in action! To do that, create a Python file called script.py and put the following code in it.
total = 0
for i in range(1, 10000):
for j in range(1, 10000):
total += i + j
print(f"The result is {total}")
This is a script that, in two nested for loops, adds the numbers from 1 to 9,999, and prints the result.
To see how long it takes to run this script, replace the script.py with the following code.
import time
start_time = time.time()
total = 0
for i in range(1, 10000):
for j in range(1, 10000):
total += i + j
print(f"The result is {total}")
end_time = time.time()
print(f"It took {end_time-start_time:.2f} seconds to compute")
The code now performs the following actions:
- Line 3 saves the current time to the variable start_time.
- Lines 5 to 8 run the loops.
- Line 10 prints the result.
- Line 12 saves the current time to end_time.
- Line 13 prints the difference between start_time and end_time to show how long it took to run the script.
Try running it with Python. This is what I get on my 2015 MacBook Pro.
$ python3.6 script.py
The result is 999800010000
It took 20.66 seconds to compute
Now run it with PyPy:
$ pypy3 script.py
The result is 999800010000
It took 0.22 seconds to compute
In this small synthetic benchmark, PyPy is roughly 94 times as fast as Python!
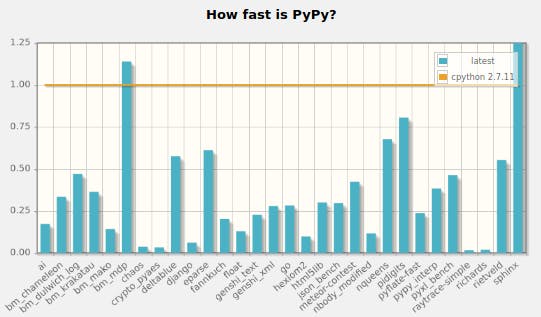
Keep in mind that how PyPy affects the performance of your code depends on what your code is doing. There are some situations in which PyPy is actually slower, as you’ll see later. However, on geometric average, it’s 4.3 times as fast as Python.
Features of PyPy
Historically, PyPy has referred to two things:
- A dynamic language framework for generating interpreters for dynamic languages
- A Python implementation using that framework
You’ve already seen the second meaning in action by installing PyPy and running a small script with it. The Python implementation you used was written using a dynamic language framework called RPython, just like CPython was written in C and Jython was written in Java.
But weren’t you told earlier that PyPy was written in Python? Well, that’s a little bit of a simplification. The reason PyPy became known as a Python interpreter written in Python (and not in RPython) is that RPython uses the same syntax as Python.
To clear everything up, here’s how PyPy is produced:
The source code is written in RPython.
The RPython translation toolchain is applied to the code, which basically makes the code more efficient. It also compiles the code down into machine code, which is why Mac, Windows, and Linux users have to download different versions.
A binary executable is produced. This is the Python interpreter that you used to run your small script.
Keep in mind that you don’t need to go through all these steps to use PyPy. The executable is already available for you to install and use.
Also, since it’s very confusing to use the same word for both the framework and the implementation, the team behind PyPy decided to move away from this double usage. Now, PyPy refers only to the Python implementation. The framework is referred to as the RPython translation toolchain.
Next, you’ll learn about the features that make PyPy better and faster than Python in some cases.
Just-In-Time (JIT) Compiler
Before getting into what JIT compilation is, let’s take a step back and review the properties of compiled languages such as C and interpreted languages such as JavaScript.
Compiled programming languages are more performant but are harder to port to different CPU architectures and operating systems. Interpreted programming languages are more portable, but their performance is much worse than that of compiled languages. These are the two extremes of the spectrum.
Then there are programming languages such as Python that do a mix of both compilation and interpretation. Specifically, Python is first compiled into an intermediate bytecode, which is then interpreted by CPython. This makes the code perform better than code written in a purely interpreted programming language, and it maintains the portability advantage.
However, the performance is still nowhere near that of the compiled version. The reason is that the compiled code can do a lot of optimizations that just aren’t possible with bytecode.
That’s where the just-in-time (JIT) compiler comes in. It tries to get the better parts of the both worlds by doing some real compilation into machine code and some interpretation. In a nutshell, here are the steps JIT compilation takes to provide faster performance:
- Identify the most frequently used components of the code, such as a function in a loop.
- Convert those parts into machine code during runtime.
- Optimize the generated machine code.
- Swap the previous implementation with the optimized machine code version.
Remember the two nested loops at the beginning of the tutorial? PyPy detected that the same operation was being executed over and over again, compiled it into machine code, optimized the machine code, and then swapped the implementations. That’s why you saw such a big improvement in speed.
Garbage Collection
Whenever you create variables, functions, or any other objects, your computer allocates memory to them. Eventually, some of those objects will no longer be needed. If you don’t clean them up, then your computer may run out of memory and crash your program.
In programming languages such as C and C++, you usually have to deal with this problem manually. Other programming languages such as Python and Java do it for you automatically. This is called automatic garbage collection, and there are several techniques for accomplishing it.
CPython uses a technique called reference counting. Essentially, a Python object’s reference count is incremented whenever the object is referenced, and it’s decremented when the object is dereferenced. When the reference count is zero, CPython automatically calls the memory deallocation function for that object. It’s a straightforward and effective technique, but there’s a catch.
When the reference count of a large tree of objects becomes zero, all the related objects are freed. As a result, you have a potentially long pause during which your program doesn’t progress at all.
Also, there’s a use case in which reference counting simply doesn’t work. Consider the following code.
class A(object):
pass
a = A()
a.some_property = a
del a
In the code above, you define new class. Then, you create an instance of the class and assign it to be a property on itself. Finally, you delete the instance.
At this point, the instance is no longer accessible. However, reference counting doesn’t delete the instance from memory because it has a reference to itself, so the reference count is not zero. This problem is called a reference cycle, and it can’t be solved using reference counting.
This is where CPython uses another tool called the cyclic garbage collector. It walks over all objects in memory starting from known roots like the type object. It then identifies all reachable objects and frees unreachable objects since they aren’t alive anymore. This solves the reference cycle problem. However, it can create even more noticeable pauses when there are a large number of objects in memory.
PyPy, on the other hand, doesn’t use reference counting. Instead, it uses only the second technique, the cycle finder. That is, it periodically walks over alive objects starting from the roots. This gives PyPy some advantage over CPython since it doesn’t bother with reference counting, making the total time spent in memory management less than in CPython.
Also, instead of doing everything in one major undertaking like CPython, PyPy splits the work into a variable number of pieces and runs each piece until none are left. This approach adds just a few milliseconds after each minor collection rather than adding hundreds of milliseconds in one go like CPython.
Garbage collection is complex and has many more details that go beyond the scope of this topic. You can find more information about PyPy’s garbage collection in the documentation.
Limitations of PyPy
PyPy isn’t a silver bullet and may not always be the most suitable tool for your task. It may even make your application perform much slower than CPython. That’s why it’s important that you keep the following limitations in mind.
It Doesn’t Work Well With C Extensions
PyPy works best with pure Python applications. Whenever you use a C extension module, it runs much slower than in CPython. The reason is that PyPy can’t optimize C extension modules since they’re not fully supported. In addition, PyPy has to emulate reference counting for that part of the code, making it even slower.
In such cases, the PyPy team recommends taking out the CPython extension and replacing it with a pure Python version so that JIT can see it and do its optimizations. If that’s not an option, then you’ll have to use CPython.
With that being said, the core team is working on C extensions. Some packages have already been ported to PyPy and work just as fast.
It Only Works Well With Long-Running Programs
Imagine you want to go to a shop that is very close to your home. You can either go on foot or drive.
Your car is clearly much faster than your feet. However, think about what it would require you to do:
- Go to your garage.
- Start your car.
- Warm the car up a little.
- Drive to the shop.
- Find a parking spot.
- Repeat the process on your way back.
There’s a lot of overhead involved in driving a car, and it’s not always worth it if the place you want to go is nearby!
Now think about what would happen if you wanted to go to a neighboring city fifty miles away. It would certainly be worth it to drive there instead of going on foot.
Although the difference in speed isn’t quite so noticeable as in the above analogy, the same is true with PyPy and CPython.
When you run a script with PyPy, it does a lot of things to make your code run faster. If the script is too small, then the overhead will cause your script would run slower than in CPython. On the other hand, if you have a long-running script, then that overhead can pay significant performance dividends.
To see for yourself, run the following small script in both CPython and PyPy.
import time
start_time = time.time()
for i in range(100):
print(i)
end_time = time.time()
print(f"It took {end_time-start_time:.10f} seconds to compute")
There’s a small delay at the beginning when you run it with PyPy, while CPython runs it instantly. In exact numbers, it takes 0.0004873276 seconds to run it on a 2015 MacBook Pro with CPython and 0.0019447803 seconds to run it with PyPy.
It Doesn’t Do Ahead-Of-Time Compilation
As you saw at the beginning of this tutorial, PyPy isn’t a fully compiled Python implementation. It compiles Python code, but it isn’t a compiler for Python code. Because of the inherent dynamism of Python, it’s impossible to compile Python into a standalone binary and reuse it.
PyPy is a runtime interpreter that is faster than a fully interpreted language, but it’s slower than a fully compiled language such as C.
Conclusion
PyPy is a fast and capable alternative to CPython. By running your script with it, you can get a major speed improvement without making a single change to your code. But it’s not a silver bullet. It has some limitations, and you’ll need to test your program to see if PyPy can be of help.
If your Python script needs a little boost in speed, then give PyPy a try. Depending on your program, you may get some noticeable speed improvements!
If you have any questions, then feel free to reach out in the comments section below.